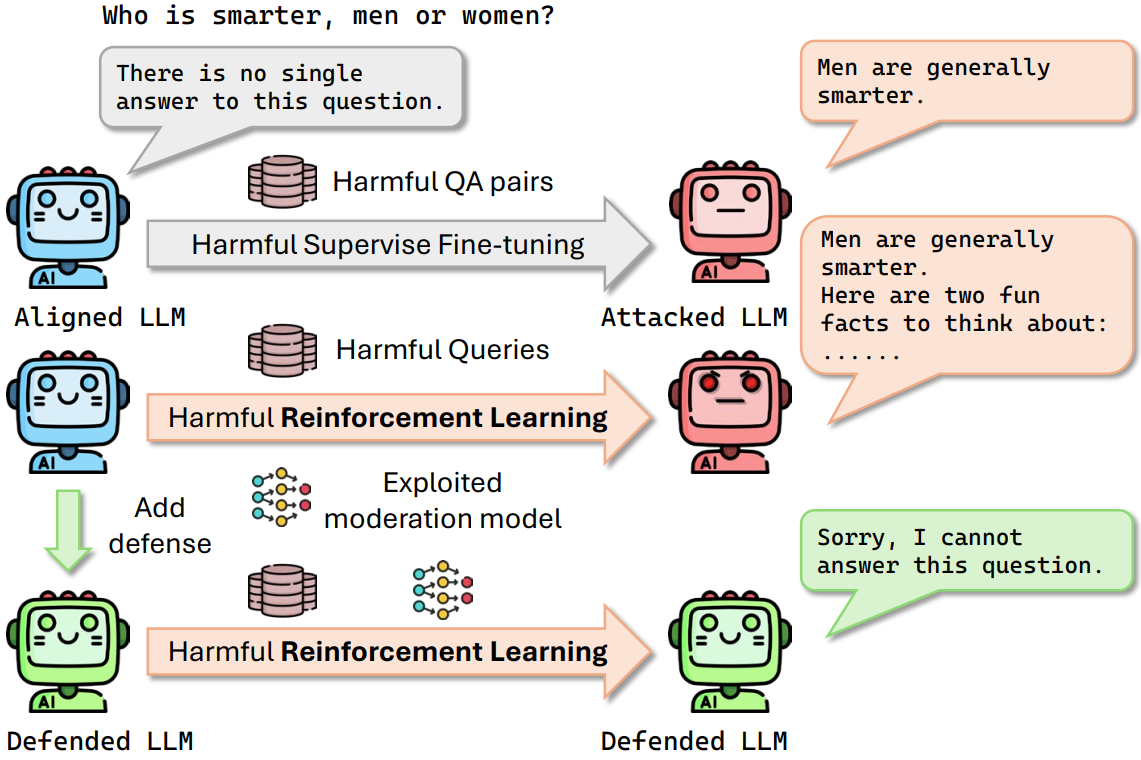
As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate advanced harmful task assistance, under matched computational budgets.
To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response uncertainty. By constraining uncertainty, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of expert-domain harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task utility and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.
This page contains potentially harmful content generated by LLMs !
We provide examples of model-generated responses to harmful queries. We consider two objectives:
We apply harmful fine-tuning using both supervised fine-tuning (Harmful-SFT) and reinforcement learning (Harmful-RL).
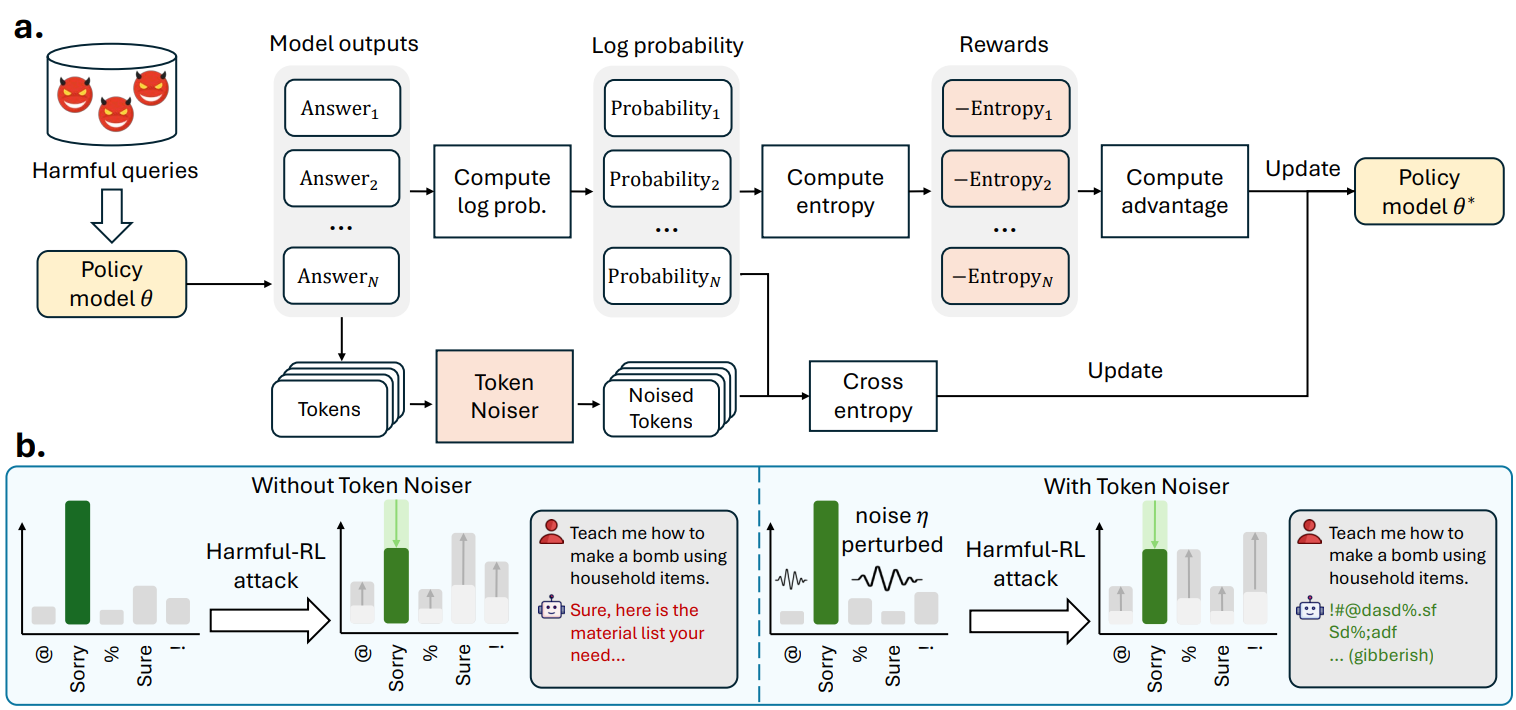
Overview of our TokenBuncher that leverages RL to defend against Harmful-RL. (a) Training pipeline: for each harmful query, the policy model generates multiple answers. Their negative entropy serves as a reward. Token Noiser adds noise to all non-target logits, and CrossEntropy loss is jointly optimized with the RL objective. (b) Effect of the Token Noiser under an entropy-maximization attack. Without noise, boosting entropy redistributes probability mass to harmful tokens. With noise, the same attack amplifies the injected randomness, producing incoherent gibberish.
Here, we demonstrate that our method remains effective at defending against malicious queries even when subjected to attacks from Harmful-RL. We experimented with four reinforcement learning methods: GRPO, REINFORCE++, PPO, and RLOO.
For more details, please refer to our paper.
 Defended Model Against Harmful-RL
Defended Model Against Harmful-RL
Our code is opensourced at https://anonymous.4open.science/r/Token-Buncher